A Data Pipeline for a Kebab Fan Club
3 April 2026, Morning:
I logged into work (late) to find no one else online… What a delightful surprise, it’s Good Friday!!!
So… high on AI Psychosis, I decided to spend the day and apply some of the ML/Data Ops stuff I’ve been doing at my internship on a little side project.
Pretext
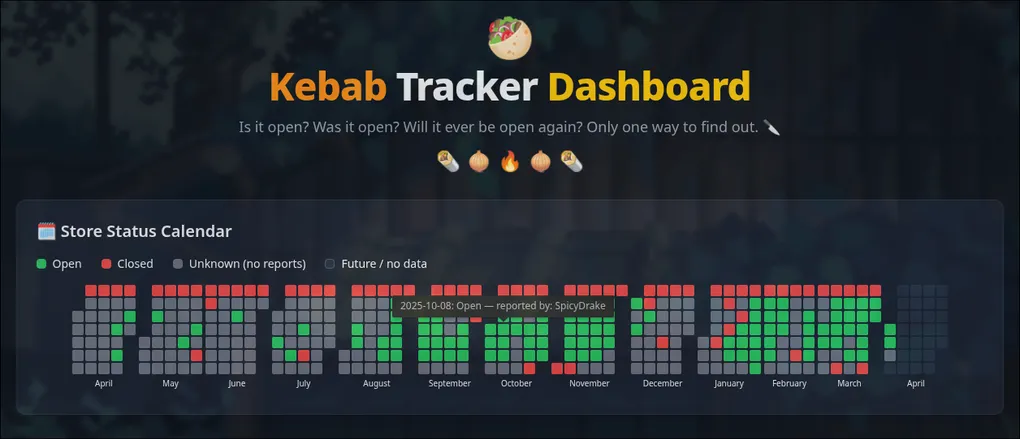
For over a year now I’ve been running a telegram chat, to crowdsource live updates on whether a specific kebab shop near my uni campus is open or not. What started as a joke, exploded into a group chat with over 1K Turks’ Kebab enjoyers.
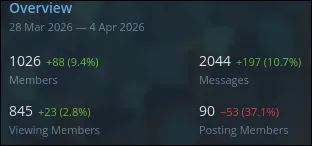
That’s a lot of people… Disappointingly, even as the group grew I felt like the participation rate and updates stayed fairly constant. I’d imagine with over a thousand people we’d be able to get daily updates but whole weeks would go by where the only chat activity was new people joining. Honestly, this broke me a little…

But, this was just my feelings, maybe I’m just crazy. THere’s NO way the group isn’t getting more active??
Only one way to know for sure…
The Data Pipeline
Hyped up by the ever sycophantic Gemini Flash, and armed with my expiring access to Claude 4.6 & Gemini 3.1 Pro (when I ran out of Claude), I knew what I had to do.
SCRAPE THE CHAT, PLOT THE TRENDS, MAKE A GOOD AND NAUGHTY LIST.
Nix flake ready, claude code purring…, and a couple prompts later… I had a full data pipeline orchestrated with Data Version Control (DVC) to incrementally scrape, parse and catalog every text, image, tele bubble/video note ever sent to the group.
The choice to use DVC to orchestrate the pipeline and manage the data over Dagster or Prefect came down to these few points:
- I’m only dealing with a couple MBs worth of data, I don’t need scale
- DVC allows easy versioning of data within git, BUT without any of it being tracked by git, allowing me to keep sensitive data private and out of commits
- DVC is simple and cool
Anyways, the pipeline is fairly simple:
- Scrape Telegram with Telethon
- Label the messages sent to find open/close data and assign attributions to the user
- Eagerly filter potential texts about the store’s opened/closed state
- Feed all images, videos and filtered text to MLLM to evaluate and label
- Aggregate and generate metrics
flowchart LR
classDef external fill:#0d2b45,stroke:#4a90d9,color:#cce5ff
classDef raw fill:#0d2e1a,stroke:#4caf50,color:#ccf0da
classDef process fill:#2e1a00,stroke:#ff9800,color:#ffe8cc
classDef llm fill:#1e0a30,stroke:#9c27b0,color:#ead6ff
classDef web fill:#001e30,stroke:#03a9f4,color:#cceeff
TG(["Telegram API"]):::external
SCRAPE["Stage 1: <br> Scrape EVERYTHING"]:::process
RAW[("Texts, Images, Videos, Member List")]:::raw
ANALYZE["Stage 2: <br> Labeling Messages <br> Eager regex filter -> MLLM Labeling"]:::process
QWEN(["Local Qwen3.5-9B (4 bit quant)"]):::llm
INTERIM[("Labeled Data")]:::raw
WEBPREP["Stage 3: <br> Anonymise & Aggregate static JSON for website"]:::process
WEB[("**** load of JSONs on <br> random metrics")]:::web
TG --> SCRAPE --> RAW --> ANALYZE
ANALYZE <--> QWEN
ANALYZE --> INTERIM --> WEBPREP --> WEB
sorry that shit is hella small if you’re on mobile
Most contributions by the group chat members was some sort of selfie in the form of a video note or picture. So it was critical to have some sort of vision model to label if the image/video contained an open kebab shop or not. Thankfully, MLLMs have gotten so good that a tiny 4 bit quantized Qwen3.5-9B model which fits in just under 8GB of VRAM is good enough to accurately label images, videos (as 6 video frames stitched tgt) and parse complicated messages like “she’s closed for the next 3 days” which requires relative date comprehension and multi-hop reasoning!! ABSOLUTE MAGIC.
I don’t have metrics on its accuracy but I tested it on the first few texts, videos and images, manually verified and tuned it till it got 100% right. Good enough for a joke project I guess!
Though it’s just a joke project I obviously don’t want to feed a bunch of random people’s faces to some random LLM API so it’s great that a tiny self-hostable model could do all this. Additionally, before generating the public facing aggregated JSONs I also made sure it anonymised the members’ tele names so I don’t dox anyone lol.
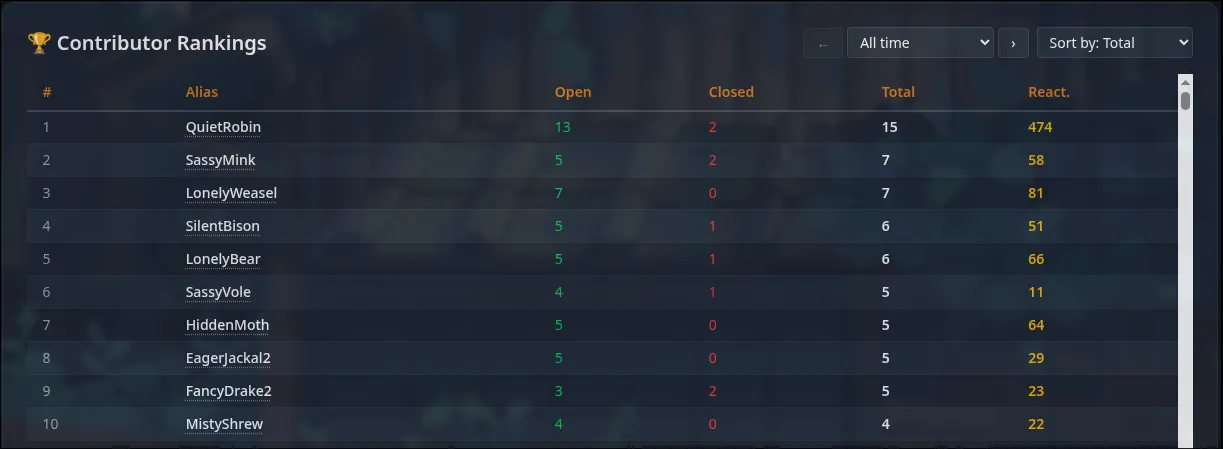
Though I do have a “backdoor” in a form of a map file which can be injected into the website to unmask all their names.
BUT, this is so I can make appreciation posts to our top monthly contributors!!
What now?
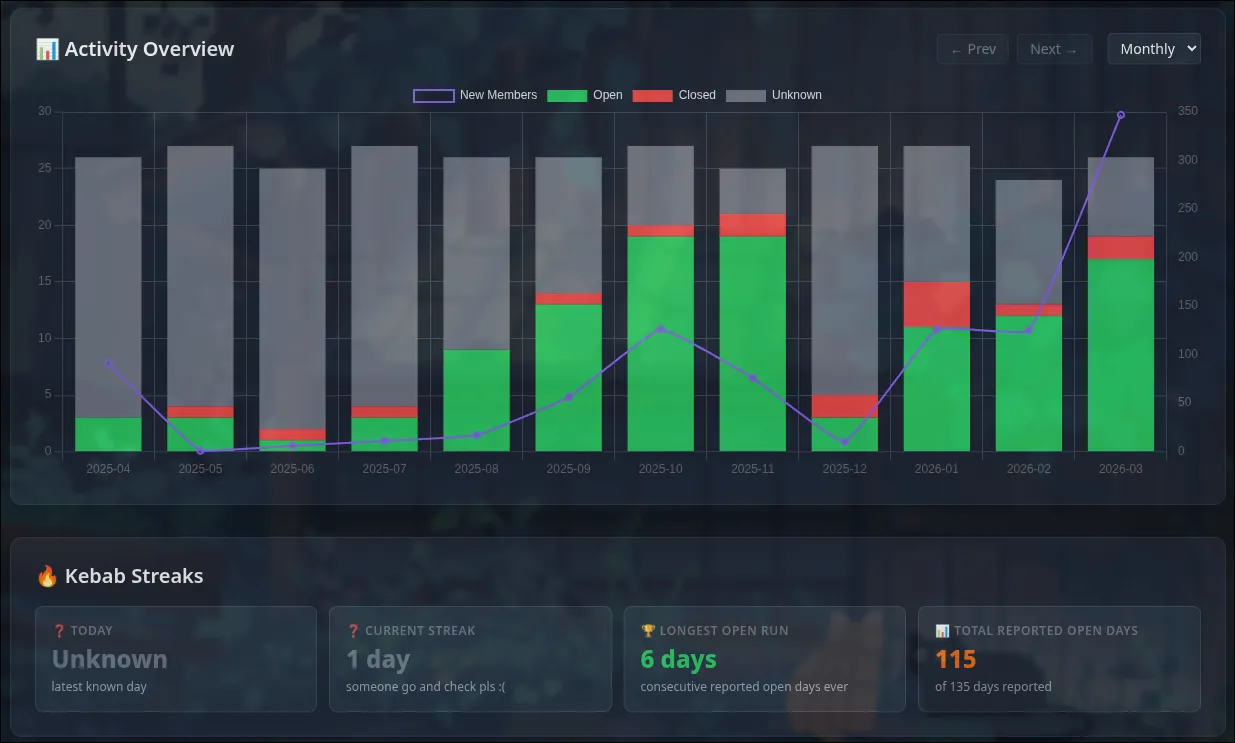
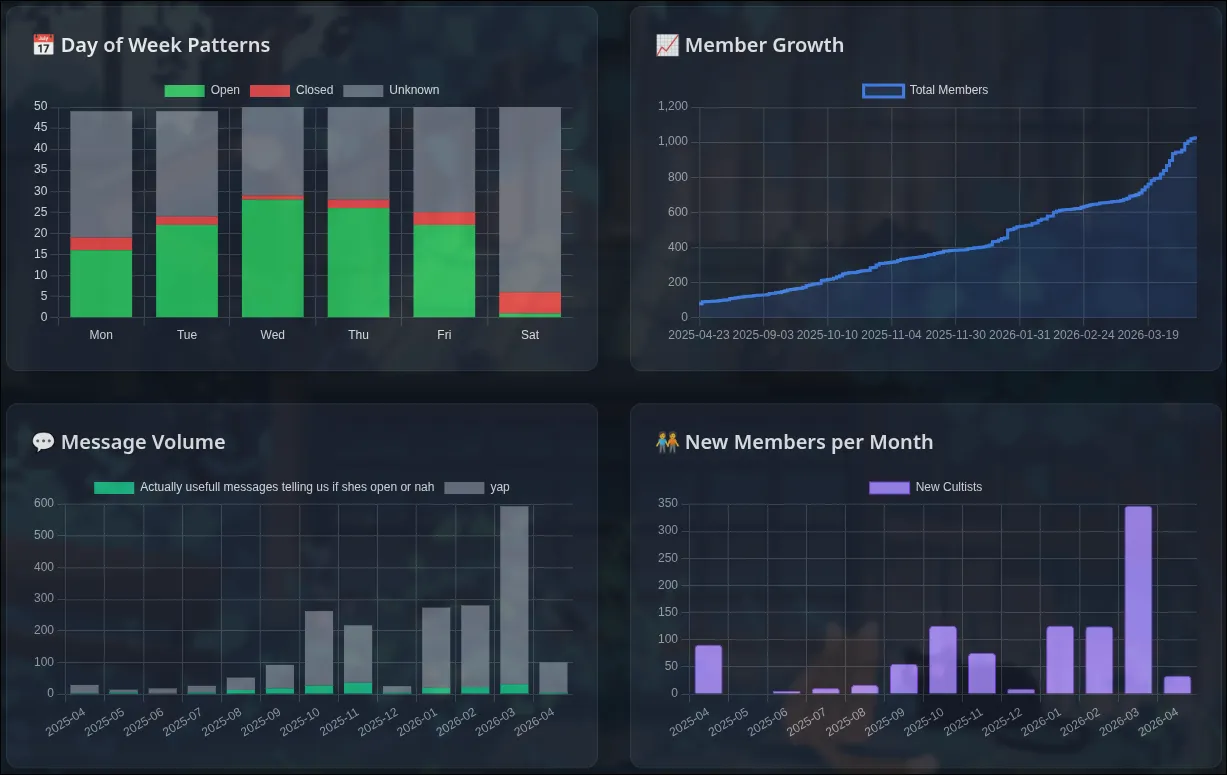
Whelp. The data showed that I WAS bein’ crazy! Engagement and participation in the group are at all time highs and the dip in december can just be attributed to winter break.
Hopefully the members of the group found the website at least a little bit funny. I also do hope the streaks and top monthly contributor list helps to increase engagement and participation.
Call me a dreamer, but I long for the day we’re freed from the lonely, anxious suspense of guessing if Turks’ Kebab is open.
In all seriousness I’ll probably be maintaining this for the next little bit. The incremental nature of the pipeline makes it cheap to run daily. But I’ll have to think of a proper solution to run this pipeline as a cron on something other than my main PC. Unfortunately, my homelab runs an old GTX1050 ti which isn’t gna work…
Links
The repo is mostly self-contained. Nix flake just handles the top level dependencies, although it’s configured to compile/pull llama.ccp for my specific hardware… So the flake is just a handy reference for what you need hehehe… There’s a make file to pull the right model and start serving the inference server! Other than that, python is managed with uv and the dashboard just uses pnpm & vite. TS with no framework cuz it dun need all dat.
Screenshots
Apart from the silly github activity like calendar at shown at the top if this blog, here’s screnshots of other visualisations